
Vous ne serez peut-être pas pénalisé – techniquement – par Google pour du contenu dupliqué, mais cela peut nuire à votre classement dans les moteurs de recherche. En effet, il est difficile pour les moteurs de recherche de déterminer quel emplacement du contenu est le plus pertinent. Par conséquent, aucune des URL n’est bien classée et aucune page ne bénéficie de la meilleure visibilité possible.
Google est censé être capable de détecter le contenu dupliqué, de regrouper toutes les URL en un seul groupe, puis de choisir le meilleur résultat. Mais cela ne fonctionne pas toujours correctement, et la mauvaise URL peut être choisie. En fin de compte, les propriétaires de sites Web peuvent constater une baisse du classement ou du trafic en raison du contenu dupliqué. Heureusement, il existe des moyens d’empêcher ce genre de choses de se produire sur vos sites.
Pourquoi le contenu dupliqué est un problème
Le contenu dupliqué a un impact sur les moteurs de recherche et les propriétaires de sites de plusieurs façons :
- Les moteurs de recherche ne savent pas quelles URLs inclure ou ne pas inclure dans les index.
- Les moteurs de recherche ne savent pas si les mesures de liens (autorité, confiance, etc.) doivent être dirigées vers une seule page ou vers plusieurs.
- Il est difficile de savoir quelle URL classer dans les SERP (pages de résultats des moteurs de recherche), et parfois l’URL indésirable peut surclasser l’URL légitime.
- L’équité des liens (l’autorité et la valeur qu’une page transmet à une autre) est diluée car les autres sites qui souhaitent inclure un lien retour vers le contenu doivent choisir entre plusieurs URL. L’équité des liens est alors répartie sur les doublons au lieu de se concentrer sur une seule page.
Même avec des URL qui renvoient toutes à votre site Web, si l’une d’elles possède des attributs de lien qui la rendent peu conviviale pour les utilisateurs et que Google classe cette version de l’URL au lieu de l’originale, les internautes risquent de ne pas vouloir cliquer dessus. Par exemple, yoursite.com/besttrails semble beaucoup plus invitant que yoursite.com/besttrails/?utm_content=buffer&utm_medium=social. Mais si Google classe le second site parce qu’il pense qu’il s’agit de la version principale du contenu dupliqué, les internautes ne cliqueront pas dessus parce qu’il est intimidant et ne semble pas digne de confiance.
En outre, le « budget » d’exploration de votre site Web est épuisé lorsque vous avez du contenu dupliqué. Google explore les sites Web pour trouver du nouveau contenu et les réinterroge périodiquement pour voir s’il y a du nouveau. Si vous avez du contenu en double sur votre site, cela signifie que l’exploration complète de toutes les pages prendra plus de temps. Cela peut entraîner un ralentissement du calendrier d’indexation et de réindexation des pages par Google et de leur affichage dans les résultats de recherche.
Règles de Google en matière de contenu dupliqué
Le contenu dupliqué sur un site ne constitue pas un motif d’action sur ce site, sauf s’il apparaît que l’intention du contenu dupliqué est d’être trompeur et de manipuler les résultats des moteurs de recherche.
Toutefois, si Google ne pénalise pas les propriétaires de sites Web pour la plupart des cas de contenu dupliqué, l’entreprise poursuit :
Dans les rares cas où Google perçoit que du contenu dupliqué peut être présenté dans l’intention de manipuler nos classements et de tromper nos utilisateurs, nous procéderons également aux ajustements appropriés dans l’indexation et le classement des sites concernés. En conséquence, le classement du site peut en souffrir, ou le site peut être entièrement supprimé de l’index Google, auquel cas il n’apparaîtra plus dans les résultats de recherche.
Qu’est-ce que Google peut considérer comme une intention de tromper les utilisateurs et/ou de manipuler le classement des moteurs de recherche ? La création intentionnelle de domaines, sous-domaines et pages au contenu dupliqué. De même, la publication de contenu récupéré, surtout si vous n’y ajoutez rien d’autre de valeur.
Mais n’oubliez pas ceci : Même si Google ne vous pénalise pas officiellement ou ne considère pas votre contenu dupliqué comme malveillant, il peut néanmoins nuire à vos efforts de référencement. Si Google a cessé de classer votre site en raison de problèmes de contenu dupliqué, vous pouvez soumettre une demande de réexamen une fois les problèmes résolus.
Comment le contenu dupliqué se produit-il ?
En général, le propriétaire d’un site Web ne crée pas délibérément du contenu dupliqué. C’est pourquoi Google ne le pénalise pas trop lourdement. C’est également la différence entre un contenu copié et un contenu dupliqué.
On parle decontenu copié lorsque vous reprenez le libellé exact d’un autre site Web et le publiez sur votre propre site. Le contenu dupliqué, c’est lorsque vous avez accidentellement ou sans le savoir une autre version de votre propre contenu quelque part en ligne.
Ici, nous allons passer en revue les façons courantes dont le contenu dupliqué se retrouve en ligne. Ensuite, nous verrons comment résoudre le problème du contenu dupliqué.
Pages HTTP, HTTPS, WWW et non-WWW
Si votre site a deux versions différentes – www.yoursite.com et yoursite.com, par exemple – le même contenu se retrouvera sur les deux versions du site, ce qui signifie qu’il y a du contenu dupliqué. Il en va de même pour les sites http:// et https://.
Pagination
La pagination peut se produire lorsqu’un article ou la section des commentaires d’un article de blog s’étend sur plusieurs pages. Ou encore, une galerie d’images, chacune d’entre elles se trouvant sur une page distincte. Ce type de duplication peut également se produire sur une page à défilement infini, où le nouveau contenu s’affiche au fur et à mesure que l’utilisateur fait défiler la page.
Variations d’URL
Les paramètres d’URL, comme les codes de suivi, peuvent créer involontairement du contenu en double. Par exemple, une page de votre site Web peut être yoursite.com/sneakers, mais si vous disposez d’un code de suivi pour savoir d’où les internautes ont cliqué, elle pourrait ressembler à yoursite.com/newsletter?utm_source=newsletter. Même si Google et d’autres moteurs de recherche ne considèrent pas qu’il s’agit d’un contenu dupliqué, vous risquez de devoir gérer les paramètres distincts qui créent des entrées multiples dans vos plateformes d’analyse.
LesID de session peuvent avoir le même effet. Une session est un bref historique de ce qu’un visiteur fait sur un site Web, comme lorsqu’il ajoute quelque chose à son panier. La session est conservée lorsque la personne clique sur d’autres pages, de sorte que son panier reste intact. L’ID de session est le modificateur unique de cette session, et il est parfois stocké dans l’URL (yoursite.com?sessionId=jow8082345hnfn8456). Cela peut créer plusieurs URL différentes avec le même contenu de page.
La même chose peut se produire si vous avez une version imprimable ou une version adaptée aux téléphones portables du contenu. Les moteurs de recherche penseront qu’il y a plusieurs pages du même contenu. Parce que… c’est le cas.
Ce phénomène est également fréquent sur les sites de commerce électronique, notamment lorsque les utilisateurs filtrent les résultats de recherche. L’URL reste à peu près la même, mais avec un ajout à la fin, comme la taille ou la couleur. C’est ce qu’on appelle la navigation à facettes ou filtrée. Le contenu des pages est pratiquement le même, mais les URL sont uniques.
Même les barres obliques de fin de ligne peuvent rendre une URL unique. Par exemple, yoursite.com/page et yoursite.com/page/. Le moyen le plus rapide de voir si cela pose un problème de contenu dupliqué est d’aller sur les deux versions d’une page. Si l’une ne se charge pas, vous n’avez pas à vous en préoccuper. Sinon, la redirection est une option (nous y reviendrons).
Autres façons dont le contenu en double peut se produire
- Descriptions de produits de commerce électronique : Il est fréquent que différents sites de commerce électronique aient du contenu en double lorsqu’ils utilisent la description d’un produit par le fabricant.
- Pages de pièces jointes : Lorsque chaque image jointe a une page distincte, cela peut créer du contenu en double.
- Pages de résultats de recherche : Elles ajoutent un paramètre à l’URL de recherche, comme yoursite.com?q=search-term.
- Environnement de simulation : Il s’agit d’une version dupliquée de votre site utilisée pour les tests.
- Pages de balises et de catégories : Lorsque vous utilisez une balise ou une catégorie, WordPress crée automatiquement des pages dédiées à la balise et à la catégorie. Cela peut parfois causer du contenu dupliqué lorsqu’une page a plusieurs catégories ou tags.
Comment résoudre le problème du contenu dupliqué
Pour certains des problèmes mineurs énumérés ci-dessus, vous pouvez trouver un paramètre dans votre plugin de référencement qui vous aidera. Par exemple, dans le plugin Yoast, vous pouvez désactiver les URL de pages jointes pour les images :
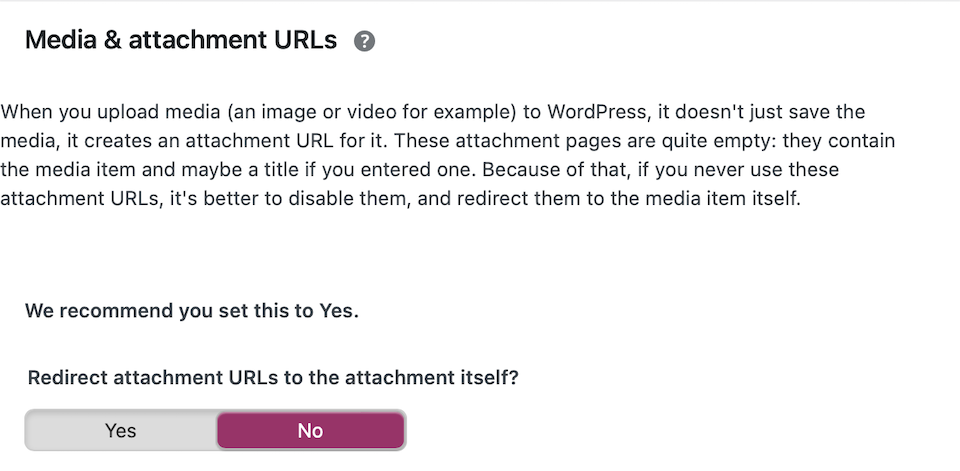
WordPress dispose également d’une option intégrée pour désactiver la pagination des commentaires :
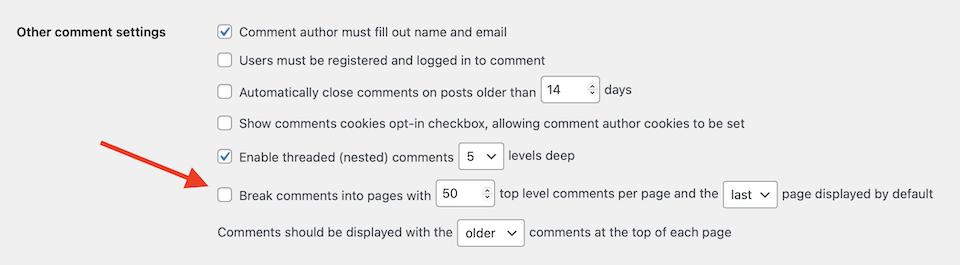
Sinon, cependant, les pratiques suivantes sont les principaux moyens de résoudre les problèmes de contenu dupliqué.
1. Trouver le contenu dupliqué
Tout d’abord, vous devez trouver les occurrences de contenu dupliqué. Des outils tels que Ahrefs Site Audit et Google Search Console peuvent parcourir votre site et vous indiquer s’il y a des avertissements de contenu dupliqué.
Si vous essayez de trouver du contenu dupliqué sur votre site pour un mot clé spécifique, vous pouvez le taper dans Google :
site:yoursite.com intitle : mot-clé
Vous verrez alors toutes les pages de votre site Web qui contiennent ce mot clé. En règle générale, il est préférable de rechercher un mot clé spécifique afin de faciliter l’analyse des résultats.
Si vous pensez qu’un article particulier a été reproduit ailleurs en ligne, vous pouvez utiliser un vérificateur de plagiat comme Grammarly ou Copyscape pour trouver d’autres exemples de phrases identiques. Vous pouvez également coller une ou deux phrases complètes dans Google pour voir si elles apparaissent ailleurs que sur votre site.
2. Ajustez l’URL du contenu grâce à la canonisation
Une fois que vous savez qu’il y a du contenu dupliqué en ligne, il est temps de déterminer quelle est la page principale à conserver.
Vous canonisez cette page principale pour les moteurs de recherche. La canonisation indique aux moteurs de recherche qu’une URL est la version principale d’une page et que cette page doit apparaître dans les résultats de recherche à la place de tous les doublons que le moteur peut rencontrer. Voici deux façons de canoniser du contenu :
redirection 301
Créez une redirection 301 de la ou des pages dupliquées vers la page principale. Les pages en double cesseront d’être en concurrence les unes avec les autres, et la page principale deviendra plus populaire et plus pertinente, ce qui signifie qu’elle commencera à être mieux classée. Nous avons un article sur la façon de créer des redirections avec WordPress pour vous aider.
Vous bénéficiez également de l’avantage supplémentaire que représente le transfert de l’autorité de la page et du jus de lien de l’URL redirigée vers la nouvelle cible.
Attribut Rel= »canonical
Cet attribut permet aux moteurs de recherche de savoir qu’une page est une copie d’une URL et que les liens, les mesures et le pouvoir de classement doivent être appliqués à l’URL principale spécifiée, et non à la page copiée. L’attribut doit être inclus dans l’en-tête HTML de chaque page dupliquée, avec un lien vers la page originale sur laquelle vous souhaitez mettre l’accent. Google propose une documentation qui explique en détail comment ajouter l’attribut, et nous avons un contenu plus détaillé sur les URL canoniques et WordPress pour compléter cette documentation.
Pour éviter le « content scraping », c’est-à-dire lorsque des robots copient, téléchargent et repostent le contenu de votre site Web, ajoutez l’attribut rel= »canonical » à vos propres pages Web. L’attribut sera autoréférentiel – il pointera vers l’URL sur laquelle il se trouve actuellement. Même si le contenu est gratté, tant que les robots transportent le code HTML complet, votre version sera toujours considérée comme l’original.
3. Ajustez les URL de votre domaine à l’aide de la console de recherche Google
La console de recherche Google vous permet de désigner le domaine préféré de votre site Web, comme par exemple yoursite.com au lieu de www.yoursite.com. Vous pouvez également indiquer à Googlebot comment traiter les différents paramètres d’URL. Cela peut permettre de résoudre une partie ou la totalité de vos problèmes de contenu dupliqué. Mais uniquement avec Google. Pas avec les autres moteurs de recherche. Des plateformes telles que Bing et Yandex disposent de leurs propres outils pour les webmasters.
Autres conseils pour prévenir ou corriger le contenu dupliqué
-
- Lorsque vous ajoutez des liens internes, utilisez la même version du domaine, que ce soit avec ou sans www
, par exemple. De même, utilisez toujours la même version d’une page, avec ou sans barre oblique de fin de ligne. La structure que vous choisissez n’a pas d’importance, mais soyez cohérent avec elle.
- Si vous prenez des dispositions pour que le contenu soit syndiqué, le site Web qui utilise le contenu doit ajouter un lien retour vers le contenu original. Pas une variation de l’URL. Mais l’URL originale, principale et canonique.
- Ne publiez pas de pages vides en tant qu’espaces réservés. Chaque page vide sera indexée, ce qui peut faire penser au moteur de recherche que vous avez beaucoup de contenu dupliqué.
- Réduisez la quantité de contenu similaire que vous avez. Par exemple, disons que vous avez un site Web juridique et que vous vous adressez à différents comtés de votre région. Chaque page spécifique à un comté peut contenir des informations similaires si vous parlez du même sujet juridique, comme les blessures corporelles. Vous pouvez fusionner la page dans une page plus grande consacrée aux deux comtés, ou varier le contenu pour que les pages restent distinctes.
Dernières réflexions sur le contenu dupliqué
Le fait de rencontrer une petite quantité de contenu dupliqué n’est généralement pas une source d’inquiétude. En revanche, les problèmes techniques qui touchent des centaines ou des milliers de pages doivent être résolus. De plus, il n’y a pas de mal à résoudre tous les problèmes de contenu dupliqué. Cela fait partie de la gestion d’un site épuré et performant. Après tout, la dernière chose que vous voulez faire est de vous faire concurrence et de ruiner votre propre classement à cause d’un contenu dont vous avez le contrôle total.
Une fois que vous avez résolu le problème du contenu dupliqué, vous pouvez également consulter notre article sur la façon de gérer la cannibalisation des mots clés pour éviter les problèmes de mots clés dupliqués.
Comment avez-vous réussi à gérer le contenu dupliqué sur vos sites ? Parlons de stratégies concrètes dans les commentaires !

